Data sources come in all shapes and sizes. Some include all of the features needed to easily integrate into load processes. Others can cause all kinds of trouble during the initial design and on an ongoing basis. One of the most important features that a data source provides is the ability to identify changed records.
Changes are typically captured in one of two ways. A record can be updated, or a new version can be created. In either case a simple [modified_datetime] field provides key information to ETL developers. In short, this field can be used to incrementally extract data. The method is simple. Select all source records that have a [modified_datetime] which is greater than the maximum [modified_datetime] in all previously collected records.
In the absence of a [modified_datetime] field we have a few options for extracting data. 1 – Change data capture can be implemented when the source supports such an option. 2 – The source system can be altered to track changes. 3 – We can extract all records and identify changes using PSA.
After determining which records to extract, there are likely other challenges ahead. Before jumping into the challenges, let’s itemize the types of source data changes that can occur. Details on CRUD operations can be found here.
- Update Record
- Delete Record
- Create Record
Creating a new record doesn’t typically cause any issues as long as the record is unique. On the other hand, deleting a record and updating a record can cause serious issues. In this post I am focusing only on updated records that do not have a [modified_datetime] field.
Options for handling updated records
Load PSA as Normal
Let’s assume that we have our Persistent Stage Area (PSA) set to track changes on all source fields. When PSA is loaded a new record will be created if an exact match does not exist in PSA currently. This works great in most cases. Even without knowing when the source was modified we can still use PSA to determine if the record is new or changed.
There is one problem though. What if the source data has a “change back”? By change back I mean the value of a field was changed back to a previous value (A to B to A). If no other fields were modified, then the merge into PSA will find a match & will not create a new record. Without a new record in PSA all downstream processes will never see this record.
Truncate PSA
If we truncate PSA prior to loading new records, then we can be ensured that all of the sourced records will be loaded into PSA. Downstream processes will also receive all records. There are some clear disadvantages though. In this case we lose all of the advantages that PSA offers. Additionally, in many systems the requirement to load all records is simply too taxing on resources and often is too time consuming.
Maintain a Current Dimension
If we could merge into PSA while only considering the current version of all records, then we could overcome the change back issue. However, all records in PSA are current by definition. We have identified the fields that should have changes tracked, and all records in PSA contain unique values for these fields.
Before determining which records are current we need to first define the business key. This will be a subset of the fields that PSA is tracking changes on. Therefore, there may be more than one record with the same business key. Which one is the current record? To determine this we need a dimension. The following processes describe how to use a dimension to identify the current record based on selected business keys and use this information to solve the change back issue.
The first challenge is to mark all PSA records as being current or not current based on the selected business key. The source data should have an [isCurrent] field added with a value of 1 by default (explained below). This will be the field that we update to 0 if the record is not current and 1 if it is current.
We also need a [UniqueID] field and a load status field as shown in the below image. The green fields are part of the source, red fields are created using expressions in PSA, and black are managed by LeapFrogBI internally.

In this example let’s assume the business key is [Src_ID]. We have two records currently in PSA with a business key set to 45. We now need to update PSA such that only the current record has an [isCurrent] value equal to 1.
The next step is to create a dimension solely for the purpose of tracking the current record. The dimension should have the business key set as the dimension key. The only other field required is the [UniqueID] which will be tracked as SCD1. Only records that have not been procesed ([ls_CurDim] = 0) will be loaded into the dimension.
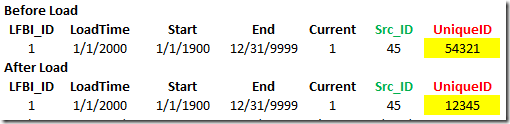
Based on our sample data the above image shows how the dimension looked before the load was completed and after the load was completed. Notice that the [UniqueID] is now set to the value of the last processed record. This dimension can now be used to update PSA’s [isCurrent] field.
Updating PSA can be done by joining PSA to the dimension on the business key. We can be assured that there is only one related record in the dimension. With this information a simple case statement can be used to set [isCurrent] to 1 if the PSA [UniqueID] matches the dimension [UniqueID]. All other records should be set to 0. To make this process more efficient a filter should be applied to the PSA records so that only records with a [isCurrent] value of 1 are evaluated. Additionally, all records should have their load status field set to 1 (processed).
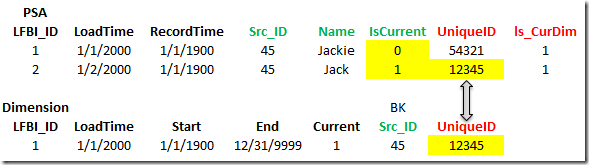
In the above image we can see that the join on [UniqueID] identified the current record, [isCurrent] has been updated appropriately, and the load status field, [ls_CurDim], has been marked as processed.
With PSA’s [isCurrent] field updated we can now load new records into PSA. Remember that the new records have a constant value of 1 added for [isCurrent]. This ensures that none of the non-current records will match the records being merged into PSA & resolve the change back issue. In our simple example the source SQL would be similar to the below.
![]()
After loading PSA we will see that a change back has been recorded. The name attribute started as “Jackie”, was changed to “Jack”, and finally was changed back to “Jackie”. We can also see that our newly loaded “Jackie” record has not been processed which sets us up for the next load execution.

Conclusion
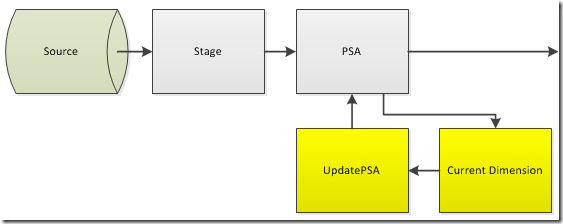
Working with source data that doesn’t mark changes can be challenging. The above solution can be used to resolve the issue that change backs present. For LeapFrogBI users all of these solutions are easily implemented. The first option, Load PSA as Normal, requires no additional action on the developers part. The second option, Truncate PSA, can be implemented by simply changing the ”TruncateTarget” configuration value to -1 (always). The third solution, Maintain a Current Dimension, requires two additional components as highlighted in the below image. With a current dimension & PSA update in place the load process can continue as normal. All downstream components will receive change backs when they occur.
If at all possible it is preferable to alter the source system to ensure that modified records are tracked. However, when this is not possible, the proposed options provide a workable solution.