Data warehousing has a clear set of objectives such as data persistence, single easy to navigate data model, fast query performance, etc… While it is not the role of the data warehouse to mimic the data in source systems, the data warehouse clearly must account for changes in the source system. Three types of changes can occur; Insert, Update, and Delete. Inserts and updates are pretty straight forward to detect and plan for. Deletes, on the other hand, require special attention and are the focus of this post. Dealing with deleted records can be broken down into three phases.
Detection – The record has been deleted from the source system. How will we learn of this delete?
Consolidation – Between the source system and the target dimensional model should include a consolidation area in most designs. How do we handle deleted records in the historical store?
Model Impact – Our dimensional model includes data that was deleted in the source system. Should this data be deleted? How do we maintain referential integrity?
This post will dive into the weeds. If you found this post and are still interested in the details that follow, please take your time and prepare for detailed reading. I have included visual aids to explain a number of scenarios. Regardless, this is not coffee table reading, and nobody will blame you for taking this topic on over several sessions. I try to keep posts to well under 1000 words, but this one is an exception.
Detecting Source System Record Deletes
There are a number of ways to detect deleted records in source systems. Below is a list of some of the most common methods. This post is not going to go into the implementation details of each method. I’ll consider focusing on individual methods in future posts.
Source System Soft Deletes – If you are lucky enough to have a source system that soft deletes records, then I recommend buying a lottery ticket right away. This is your lucky day. What is a soft delete? Instead of deleting a record, the record is marked as being deleted typically by a dedicated column. Detecting deletes means that you simply need to select the records where the record has been flagged as having been deleted. Simple as that.
Hard Delete with Audit Trail – Some source systems will delete records, but will also story this history in some way to support undo and audit trail type functionality. You may need to do a little fishing, but in this case detecting a deleted record is just a matter of finding the history which may reside outside of the original location.
Hard Delete with No Trail – This scenario here is that the source system has hard deleted a record and left no trace of the record. This is not your lucky day. So, if the record is gone, then how can we detect this deletion? Here are a few options. Again, I’m not going into implementation details.
- Compare to consolidation. The idea is that you have collected records from the source system on a regular interval. This means that the real question is, “what has been deleted since I last collected source records?” To determine this we can compare every record in our consolidation area (PSA) to what still exist in the source system. Anything that exist in PSA, but does not exist in the source has been deleted. Yes, this can be a very expensive process, but with some filters and fancy comparison logic we can often find ways to limit the comparison to only records with timestamps newer than the prior period comparison.
- Search the logs. There is a chance that the deleted record still exist in the source system transaction log. No guarantee though. You will need to understand how logs function in the source system database to determine if this is an option.
- Implement change data capture. Change data capture can records all record manipulations for you automatically as they occur. We can then query the CDC data to pull out deletes directly. To implement this you will need to have adequate control over the source system.
- Implement last change. Like CDC, last change will automatically store record manipulation details. Unlike CDS, however, last change only persist the “last change” to each record. This may be all you need though. Check with your source system to see if this is an option. Again, you will need source system authority to implement this feature.
- Create triggers. Use triggers to store deleted record details. This method may or may not be supported by your source system and has some known limitations. Personally, I don’t recommend it, but it is an option. Of course, the trigger will be created on the source system so you will need adequate privileges.
- Use backups. If your source system is being backed up regularly, then you may try to detect deletions by comparing prior versions of the source system to the current version of the source system. It is often easier to use PSA as the source of comparison, but if you don’t have a PSA then you may need to look for other options.
One other point that is important to not forget is that source systems often archive records. This may be done on a schedule, manually, or can even be event driven. When this archive occurs, we don’t want to consider these records to be deleted. Be sure to learn how your source systems behaves. The same is true for restored archives. Also, if you are sourcing data from multiple souce systems which end up in the same target object, then you really can’t delete the data in your target until it is deleted from all sources. We need to plan for these situations.
Dealing with Deleted Records in our Historical Store
Depending on your architecture, you likely have one of three types of layers between the source system and the target dimensional model. I advocate a consolidation area (PSA) that is an exact copy of the source system with all unique versions of all records that have ever been retrieved. Some designs include a 3nf data structure which converts the source system into a normalized structure & uses timestamps to store record effective ranges (similar to scd2 tracking). Finally, you may have no consolidation area at all. If you don’t have a consolidation area, then you have the benefit of not dealing with deletes in the consolidation area. Don’t worry, you will have plenty of fun when trying to support a changing target model. In the other two cases (PSA & 3nf) we need to come up with a strategy for dealing with deleted records.
The strategy is very simple. Never delete records from the consolidation area. Instead, mark records as having been deleted in the source system. For designs that use a 3nf structure, you will need to either identify all of the destinations where the original record has been parsed into, or you will need to mark the highest level table alone & ensure that all data retrieval operations check this table for deleted records. This undo complexity is one reason why I’m not a fan of this approach. With a single PSA that is an exact copy of the source system we support storing a full history of source system records and can easily identify which record need to be soft deleted. Note: This is my opinion. It is okay if you don’t agree. Whichever method you subscribe to I think we can all agree that we will handle source system deletes in the consolidation area using a deleted flag – no hard deletes. My preference is to leave the deleted flag field null and place a datetime value in the field when a delete is detected.
Update the Dimensional Model to Account for Source System Deletes
Ok, so now we get to the meat and potatoes of this post. I’m assuming that our data is ending up in a dimensional model. I’m also assuming that we are trying to incrementally load this model. In limited cases, it may be more efficient to simply fully (or partially) reload the target model instead of dealing with the delete at all. This option is supported if you have a consolidation area that includes a full history.
Where does the data end up? Is it in a dimension or a fact? What type of dimension? SCD1, SCD2, Hybrid? What type of fact? Periodic snapshot, accumulated snapshot, transactional? I have covered quite a few scenarios below, but in no way is this a comprehensive list. In many cases a deleted record may target two, three or more destination objects. My goal is to provide the foundation concepts that can be applied to scenarios that are covered explicitly or are derivatives of these scenarios. You will need to closely examine your situation and come up with an appropriate strategy for dealing with deleted records in the target dimensional model.

Let’s start with a baseline. The above graphic describes a very simple situation which I will base all subsequent examples on. The left column represents the source, PSA, and target for a dimension. The right represents the source, PSA, and target for a fact table. Of course, there will be other things going on between the consolidation area and the target in most cases, but I’m trying to focus the discussion only on these three layers.
Study this baseline so that subsequent examples will be easily understood. In each example I’ll detail the actions required in the described scenario.
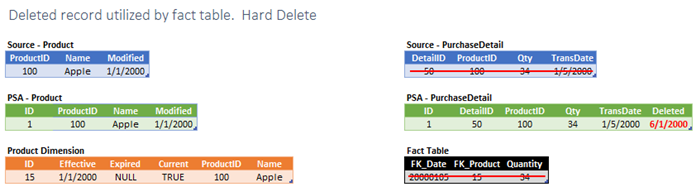
Now that you have the baseline in mind, let’s start with the simplest scenario. We detected a source system delete that is the source for a fact table. We have two options. We can either hard or soft delete the fact. This brings up an area of debate. Should we delete facts? If we do, then we are potentially changing values that were reported yesterday (prior to the delete). You can decide what works for your organization. My preference is to always soft delete, but I will cover hard delete scenarios such as this on as well.
Keep in mind that this is a limited scenario. You may have aggregation tables that are based on an atomic level transactional fact table. In this case, you will need to adjust the aggregate fact table as well.
Actions Required
- Mark PSA records as deleted.
- Delete the correlated fact record.
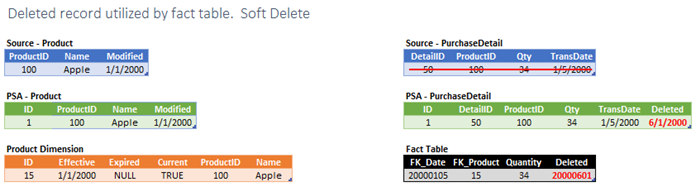
I prefer to use soft delete whenever possible. This makes it easy to explain changing measure value from one day to the next. Of course, with PSA in place we can always retrieve the historical view of a measure, but only after applying business rules which may take quite a bit of work.
Actions Required
- Mark PSA record as deleted
- Mark Fact records as deleted

In this example, I’m assuming that we are using an unknown member in the dimension. You may be using inferred members in which case you will need to create an inferred member and redirect the fact foreign key to point to this new member’s surrogate key. You may also have logic that does not allow facts to be loaded unless they successfully find a related dimension records. In this case you will need to delete the fact and set the related record to be reprocessed in PSA creating a virtual queue. Keep in mind that the fact will need to be updated prior to deleting a dimension record if you have implemented referential integrity.
Actions Required
- Mark PSA record as deleted.
- Identify fact records that reference the dimension record to be deleted.
- Update related fact foreign key values to point to the unknown member.
- Delete the dimension record.

Preferably we will not delete records from our dimension. Doing so creates a lot of complexity. An argument can be made that at the time the fact was loaded which points to a source system deleted dimension record, it was in fact related to that deleted record and should remain this way. I agree with this way of thinking. What provides more information to our users; setting the fact to point to an unknown member or leaving it to point to a deleted dimension record? The latter is more informative. Add this to the simpler implementation, and you have a strategy that is superior to hard deletes in my opinion. It is important to consider the deleted dimension record when preparing user reports. It may be more appropriate to group facts related to deleted dimension records into their own bucket, for example.
Actions Required
- Mark PSA record as deleted.
- Mark dimension record as deleted.

Now we are looking at a situation where the deleted record is used in a dimension which tracks history on a slowly changing dimension (SCD) type 2 basis. In this first scenario we are assuming that the record being deleted is not the current version; there is a newer version of the dimension key. We also are taking a hard delete approach (not recommended). The problem once again is that we need to first take care of any facts that reference the deleted dimension record. Additionally, we need to fill any effective/expired time gaps that the deleted record creates.
Actions Required
- Mark PSA record as deleted.
- Identify fact records that reference the dimension record to be deleted.
- Update related facts foreign key values to reference appropriate dimension record.
- Adjust the effective/expired values on adjacent dimension records to fill any time gaps that are created.
- Delete the dimension record.

Similar to the last example, this scenario involves a deleted source system record that is used in and SCD2 dimension. In this case the deleted record is the current version of the dimension key. Again we are taking a hard delete approach (not recommended). This scenario requires that related facts be adjusted prior to deleting the dimension record.
Actions Required
- Mark PSA record as deleted.
- Identify fact records that reference the dimension record to be deleted.
- Update related facts foreign key values to reference appropriate dimension record.
- Adjust the effective/expired values on adjacent dimension records to fill any time gaps that are created.
- Update the current record flag on prior version of dimension record.
- Delete the dimension record.
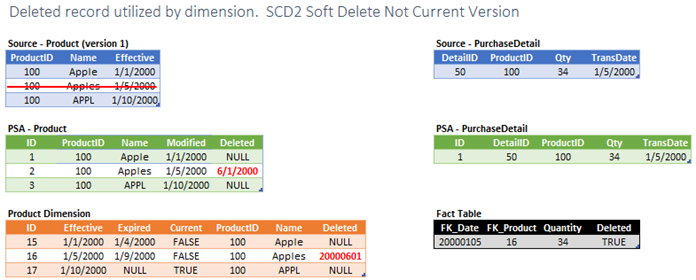
Let’s now take the same scenario, source system delete that is used in an SCD2 dimension, and apply soft delete logic. Again, the idea here is that we don’t delete the dimension record. Instead we will mark it as being deleted. We are not going to update fact foreign keys that point to the deleted record. By taking this approach we provide our users with the option to continue using the deleted dimension record based on the premise that the deleted version was effective when the fact was recorded. If the data consumer decides to not use the deleted version and instead prefers to select the last effective version, then that option is also available.
Actions Required
- Mark PSA record as deleted.
- Mark the dimension record as deleted.

Using the same logic as the above scenario, we can deal with SCD2 dimension current version deletes in a very straight forward manner. The strongest objection to this approach is that it adds the requirement for data consumers to always consider whether deleted dimension records should be included in the results which does add some overhead. If this is a major issue, then adding a semantic view of the data warehouse that resolves this in a manner that is transparent to the end user may be a viable solution.
Actions Required
- Mark PSA record as deleted.
- Mark the dimension record as deleted.

In this example we have a source system deleted record that ended up in a hybrid dimension. The column [Name] is tracked on an SCD2 basis and [Color] is tracked on an SCD1 basis. The deleted record is not the current version of the dimension key. We are taking a hard delete approach (not recommended). Because the deleted version of the dimension key is not the current version, we can handle this exactly like the above example for an SCD2 dimension. The SCD1 attribute does not need to be adjusted.
Actions Required
- Mark PSA record as deleted.
- Identify fact records that reference the dimension record to be deleted.
- Update related facts foreign key values to reference appropriate dimension record.
- Adjust the effective/expired values on adjacent dimension records to fill any time gaps that are created.
- Delete the dimension record.
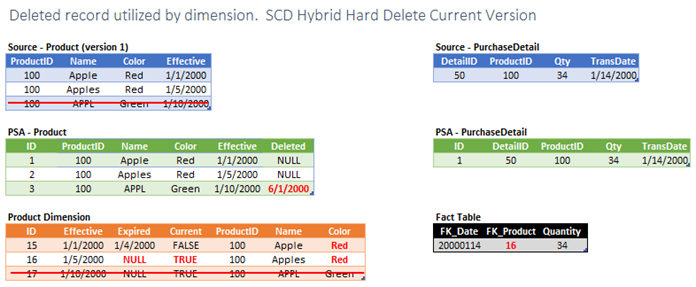
Now we have a little tougher situation. The deleted record ended is the current version of a hybrid (SCD1 & SCD2) dimension record. In addition to handling the fact foreign key & dimension SCD tracking fields, we also need to revert the [Color] field value to match the value of the last effective version. This can be a quite tricky to implement. In simple cases we will be able to determine which record in PSA sourced the prior dimension record version, but in complex scenarios this may not be feasible. It is important to plan for this situation ahead of time as it might require that some type of identifier be added to the dimension making this update possible.
Actions Required
- Mark PSA record as deleted.
- Identify fact records that reference the dimension record to be deleted.
- Update related facts foreign key values to reference appropriate dimension record.
- Adjust the effective/expired values on adjacent dimension records to fill any time gaps that are created.
- Update the current record flag on prior version of dimension record.
- Determine the value of the newly current record for all SCD1 attributes.
- Update all versions with the newly current version’s SCD1 value.
- Delete the dimension record.
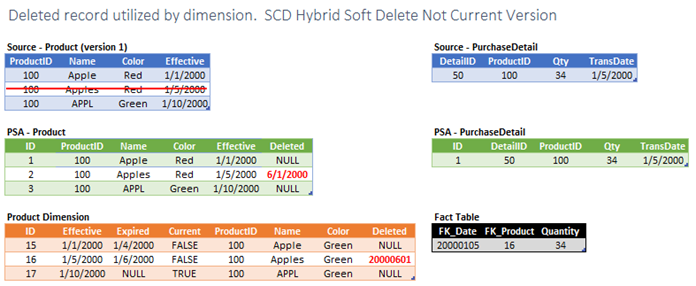
Back to the soft delete approach (recommended method). Again, this implementation is quite simple. We just mark PSA as deleted and mark the dimension record as deleted. Facts continue to point to the deleted dimension record. We can provide a semantic view to simplify access for data consumers that choose to not include deleted dimension records in their results.
Actions Required
- Mark PSA record as deleted.
- Mark the dimension record as deleted.
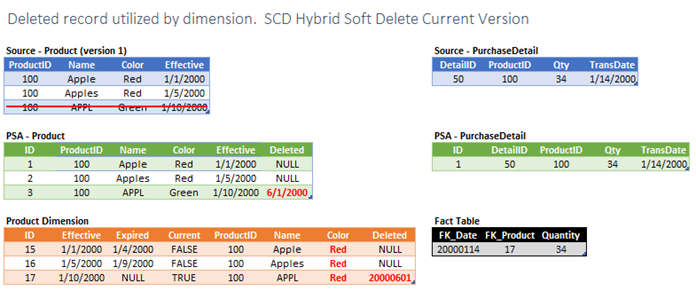
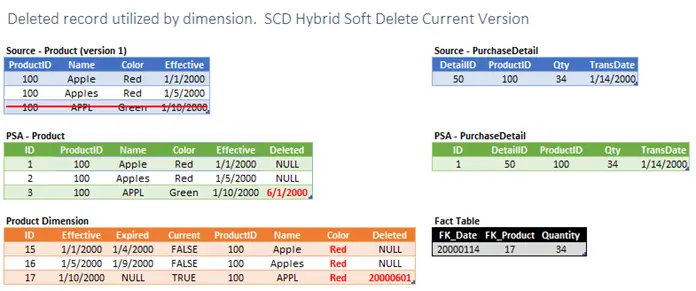
In this last scenario we have a source system delete that is the current version of a dimension key in a hybrid dimension. As with the prior scenario we simply need to mark the record as deleted in PSA and in the dimension. However, we have one more issue. The SCD1 attributes need to be updated to reflect the newly current version’s value. In the example I chose to update all versions including the deleted version. You may choose to not update the deleted version. In either case, be sure to stay consistent. Again, to accomplish this you may need to plan ahead and place an identifier that enables you to determine exactly which PSA records was used to source the newly current dimension record.
Actions Required
- Mark PSA record as deleted.
- Determine the value of the newly current record for all SCD1 attributes.
- Update all versions with the newly current version’s SCD1 value.
- Mark the dimension record as deleted.
Conclusion
Dealing with deleted source system records in a data warehouse can be quite complex. First, figure out how you will detect the delete. Then come up with a consistent strategy for dealing with the delete in your consolidation area and in the target dimensional model. Never hard delete any record from your consolidation area; use soft deletes. Whenever possible, do the same in your target model. Hard deletes are harder to deal with and add additional burden on your ETL processes.
Stay tuned for future posts and LeapFrogBI YouTube Channel videos on this topic describing in detail ETL design patterns required to support source system deletes in a data warehouse.