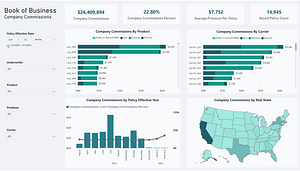
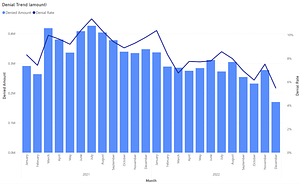
Some of the most challenging data warehousing situations come in the form of external data mashups. Because the term “data mashup” has taken on a number of meanings over the past few years, I’ll clarify how the term is used in this post.
External Data Mashup Source Data Description
- Systems of record are not in the direct control of the organization building a data warehouse
- Source systems are in no way integrated and little or no standards are enforced
- Source data quality is often low and/or inconsistent
- Data source structure is often less than ideal; paper form, pdf, Excel, flat file, etc…
- Data is not guaranteed to be sourced chronologically
- It is not always possible to determine when a record became effective
- Data often contain duplicates with little ability to accurately select survivors
Data Warehousing Goals Emphasized by External Data Mashups
- Enable an organization to understand how external influencers impact success and empower forward looking insight
- Create new data through inference based on external data mashups
- Data aggregators seek to market integrated datasets to specific interest groups
- Cleanse, conform, and de-duplicate source data providing value beyond the sum of the parts
When faced with the situation described above it is pretty easy to see how a project can quickly get off track. If things really get off track, then faith in the entire data warehousing and dimensional modeling discipline will break down. Before long people begin to believe that the data cannot be warehoused, and instead alternative technologies should be used such as NoSQL, mass storage/processing, and data virtualization technologies. Sadly, neither the lack of ACID compliance nor the ability to process limitless amounts of data will not solve complex data integration challenges such as external data mashups. The problem is much less about technology than it is about logic which can only be created by humans (for now).
Good News! External data can be integrated into a data warehouse. Dimensional modeling is up to the challenge as proven many times over. Every situation is unique, but here are a few thoughts that you may want to consider.
Avoid Refactoring caused by Late Arriving Dimension Data – When you have a source that is consistently providing data that is not in chronological order, you will soon be in a late arriving dimension situation requiring constant refactoring (fact foreign key value updates & dimension SCD tracking updates). This makes traditional SCD tracking (effective, expired, current) less than ideal. One solution is to pull attributes that requires historical values to be tracked (SCD2) into their own dimension and put a factless between the original dimension and the new dimension. The factless will include a data/time foreign key. This allows us to record factless facts without the need to refactor when events are reporting out of chronological order. The downside is that this complicates the model significantly in cases where there are many attributes requiring history to be tracked.
Lower the Bar – When dealing with external data it is often not possible and nearly always not practical to get the data into perfect form. Taking the all or nothing stance will quickly lead to nothing. As an example; data warehouses are often sourced from systems such as ERP and CRM. These systems are tied together by normalized data models with referential integrity enforced. External data, on the other hand, has no referential integrity. It sometimes doesn’t natively have natural keys at all. This leads to obvious issues when trying to relate external data from one source to external data from another or even to internal data. Compromises must be made. In an ideal world all data would pass through extensive cleansing and master data management processes before entering the data warehouse, but this is not always practical or even financially feasible. As a result we must often take a broad brush approach to core decisions such as natural key selection. Yes, errors will show up in the target model, but in some cases being less than perfect is acceptable if we can deliver an acceptable portion of the external data to an integrated warehouse. Dimensional modeling has all the tools needed to clearly isolate data with less than 100% confidence ensuring that the entire model is not compromised.
Stay Agile – The importance of sticking to agile development principals is magnified in the hairy world of external data mashups. It is all too easy to get stuck on one difficult problem and deliver nothing. It is also very easy to look at external data as a data source that must be dealt with in one pass. Resist these temptations. Take a little time to architect a general approach to the integration challenges then move forward with a bite sized piece of work that you can deliver in a single iteration. This may mean that only one dimension is able to be delivered in a sprint, but that is okay. This also means that there is not enough time to fully analyze and research all of the obstacles; also okay. Remember that agile is about steadily delivering something of value to production. Keeping the routine delivery going is very important to establishing a development rhythm. The small wins not only help developers succeed, but also helps leaderships see that measureable progress is being made on a regular basis.
Leadership & Culture – It is no secret that Business Intelligence and Data Warehousing projects fail on a routine basis. Adding in the additional burdens caused by external data integration is sure to lower the likelihood of success. This makes proper leadership and culture all that more important. Executives are not in the data warehousing war room and they are obviously not going to take the time to understand the details that make data warehousing with external data mashups so complex. This makes it very important to deliver small pieces of value often. Leaders can then asses the velocity and gain an understanding of the overall project size which will very likely be much different from planning estimates. Leadership that is directly responsible for the data warehousing effort must be able to fully understand the technical challenges, direct resources appropriately, and help higher levels of management understand what is going well and what requires strategic rethinking. It is also imperative that leaders understand when to stay the course and when to redirect. Changing direction on each challenge leads to no progress just like sticking with a no win tactic is sure to fail. Finally, be prepared to make mistakes. It will happen, and the right culture will view them as progress. Proper tooling (such as LeapFrogBI’s metadata driven ETL platform) will minimize the rework required when mistakes are made.
This is a topic that can easily consume a book or two worth of text, but hopefully this post has provided some small amount of insight into integrating external data into a data warehouse. The best advice is always to recruit and motivate skilled people, give them a clear goal, provide the best tools, and stay out of their way.